The Fastest Library for GPUs
also, hire us to accelerate your code
Easy-to-use API, like these examples


"Used by 10,000s of developers, ArrayFire is easy-to-use and blazingly fast."
Hundreds of Functions
ArrayFire supports hundreds of accelerated tensor computing functions, in the following areas:
-
-
- Array handling
- Computer vision
- Image processing
- Linear algebra
- Machine learning
- Standard math
- Signal Processing
- Statistics
- Vector algorithms
-
Data structures in ArrayFire are smartly managed to avoid costly memory transfers and to take advantage of each performance feature provided by the underlying hardware.
ArrayFire Community
The community of ArrayFire developers invites you to build with us if you're interested and able to write top performing tensor functions. Together we can fulfill The ArrayFire Mission under an excellent Code of Conduct that promotes a respectful and friendly building experience.
The community focused on excellent engineering support through good documentation and user forum.
Benchmarks
Check out our latest benchmarks. With 100x speedups on most functions, GPU computing is undeniably beneficial to most data science and technical computing projects.
All benchmarks were performed on a NVIDIA® A100 Tensor Core GPU and an Intel Xeon Platinum 8275CL CPU (3.00GHz). The benchmarks compare ArrayFire on the GPU to ArrayFire using only the CPU, taking advantage of CPU vector instructions when feasible using Intel-MKL.

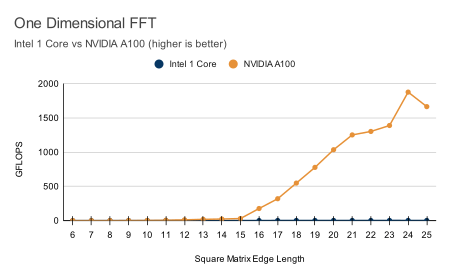


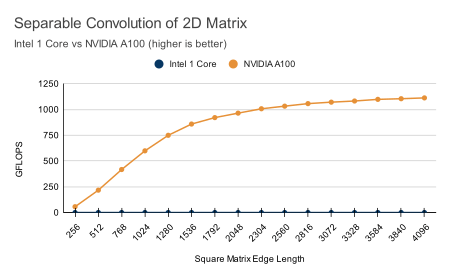
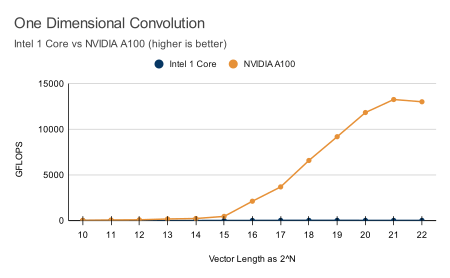
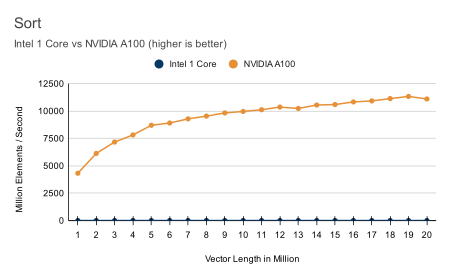
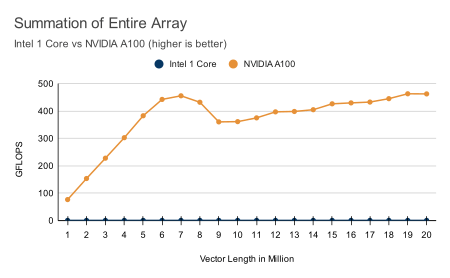
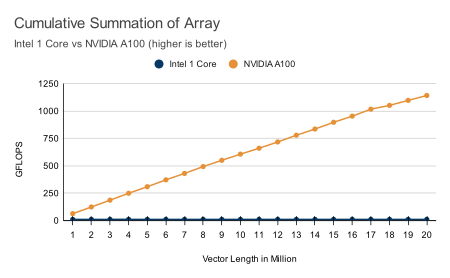
Hardware Neutral
Avoid hardware vendor lock-in and high maintenance costs with ArrayFire. With new hardware options every year, low-level CUDA™, oneAPI, or OpenCL code must be changed continually to ensure top performance. If you use ArrayFire, you can rely on us to do that work.
With ArrayFire, you program your algorithms in a higher-level array notation that remains unaffected in the future as underlying hardware architectures change. Upgrade to the latest ArrayFire library, and you can target the best GPUs, FPGAs, or other accelerators in the future.
Today, ArrayFire has backend support for CUDA-capable NVIDIA GPUs, oneAPI devices, OpenCL devices, and CPUs. With ArrayFire, you can easily switch between the backends without changing your code.

Expert Consultants for AI & GPU Computing Projects
We are a software development and consulting company with a passion for AI and GPU acceleration projects. We are experts at code acceleration, model development, and production-ready design. Our specialized expertise is in machine learning and computer vision. Our amazing customers range from startups to Fortune 500 companies in a variety of industries, including defense, finance, and media, and include government and academic research institutions. We obsess over customer value delivering the collective mindshare of our whole company to every project.
 Software Design
Software Design
We have worked with hundreds of companies and entrepreneurs to develop custom, high-performance software solutions. We use the latest software development methods, profiling tools, and deployment methods to deliver scalable solutions for your business goals.
 System Assessment
System Assessment
We also perform holistic application audits that establish the current and theoretical maximum performance your application can achieve. Our methods evaluate everything from the hardware up so you can determine bottlenecks and get the maximum return on investment for future development work.
 Training
Training