The ArrayFire library offers JIT (Just In Time) compiling for standard arithmetic operations. This includes trigonometric functions, comparisons, and element-wise operations.
At run-time, ArrayFire aggregates these function calls using an Abstract Syntax Tree (AST) data structure such that whenever a JIT-supported function is ”met,” it is added into the AST for a given variable instance. The AST of the variable is computed if one of the following conditions is met:
- an explication evaluation is required by the programmer using the eval() function member or
- the variable is required to compute a different variable that is not JIT-supported.
When the above occurs, and the variable needs to be evaluated, the functions and variables in the AST data structure are used to create a single kernel (”function-call”). This is done by creating a customized kernel on-the-fly that is made up of all the functions in the AST – the customized function is then executed.
This JIT compilation technique has multiple benefits:
- A reduced number of kernel calls – a kernel call can be a significant overhead for small data sets.
- Better cache performance – there are many instances in which the memory required by a single element in the array can be reused multiple, or the temporary value of a computation can be stored in the cache and reused by future computations.
- Temporary memory allocation and write-back can be reduced – when multiple expressions are evaluated and stored into temporary arrays, these arrays need to be allocated and the results written back to the main memory.
- Avoid computing elements that are not used – there are cases in which the AST is created for a variable; however, the expression is not used later in the computation. Thus, its evaluation can be avoided.
- Better performance – all the above can help reduce the total execution time.
// As JIT is automatically enabled in ArrayFire, this version of the function
// forces each expression to be evaluated. If the eval() function calls are
// removed, then the execution of this code would be equivalent to the
// following function.
static double pi_no_jit(array x, array y, array temp, int samples){
temp=x*x;
temp.eval();
temp+=y*y;
temp.eval();
temp=sqrt(temp);
temp.eval();
temp=temp < 1;
temp.eval();
return 4.0 sum(temp)/samples;
}
static double pi_jit(array x, array y, array temp,int samples){
temp = (sqrt(x*x+y*y) < 1);
temp.eval();
return 4.0*sum(temp)/samples;
}
The above code (using ArrayFire) computes the value π using a Monte-Carlo simulation where points are randomly generated within the unit square. Each point is tested to see if it is within the unit circle. The ratio of points within the circle and the point in the square approximate the value π. The accuracy of π improves as the number of samples is increased, which motivates using additional samples.
There are two implementations in the code listing: – an implementation that takes advantage of the JIT feature (pi_jit) – an implementation that does not benefit from the JIT (pi_no_jit).
Specifically, as JIT is an integral feature of the ArrayFire framework, it cannot simply be turned on and off. The only way for a programmer to sidestep the JIT operations is to manually force the evaluation of expressions. This is done in the non-JIT-supported implementation.

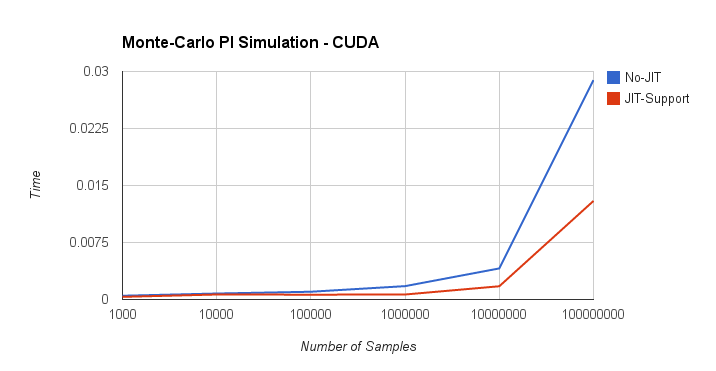{kind=link}
The above figure depicts the execution time (abscissa) as a function of the number of samples (ordinate) for the two implementations discussed above. These tests were conducted on NVIDIA K20 GPU.
When the number of samples is considerably small, the execution time of the non-JIT-supported function is dominated by the launch of multiple kernels. While the JIT-supported function only has a single kernel to launch, the creation of the JIT code dominates the execution time. Nonetheless, the JIT-supported function is 1.4X-2.0X more than the non-JIT-supported function.
In the case of a large number of samples, both the kernel launch overhead and the JIT code creation are not the limiting factors – the kernel’s functionality dominates the execution time. Specifically, the JIT-supported version is 2.0X-2.7X faster than the non-JIT support function due to the reduced number of cache misses.
The number of applications that benefit from the JIT code generation is significant. The actual performance benefits are also application dependent though we have seen similar performance curves in the past. In a recent blog, Conway’s Game of Life, we showed how to implement the “Game” in a handful of lines of code. Now that you know about JIT and what to look for, can you see how JIT is applied to the Game of Life?
Comments 3
Pingback: Performance of ArrayFire JIT Code Generation
Why did you stop publishing on Google+?
It makes harder to follow you…
Author
Thanks for the feedback. It seems like we overlooked this. We will continue to publish on Google+ as well.