We’re excited to announce the release of ArrayFire v3.10, a major update packed with improvements across the board.
But that’s not all…
🔥 We’re also officially introducing Python support (WIP)!
Now you can harness the power of ArrayFire’s high-performance GPU acceleration right from Python. This release supports the Data API Standard, allowing for drop-in replacement of popular NumPy functions (try the beta release).
Whether you’re accelerating deep learning models on GPUs, performing signal processing, or working with sparse data structures, this release provides enhanced tools and improved reliability for your numerical computing workflows.
🚀 What’s New in v3.10.0
🧠 Expanded Type Support
- Signed
int8support has been fully integrated across the library - Half-precision (
fp16) support has been significantly expanded and stabilized across multiple backends.
⚙️ Compatibility Updates
- NVIDIA CUDA support now includes versions 12.3 through 12.9, ensuring developers can utilize the latest NVIDIA GPUs and drivers.
- Intel oneAPI backend has been upgraded to oneAPI 2025.2, keeping ArrayFire up-to-date with Intel’s latest ecosystem.
🛠️ Fixes and Stability Improvements
- Sparse matrix multiplication on the OpenCL backend has been optimized for better performance.
- More examples have been added to help users learn by doing (e.g., Raytracing Black Holes, anyone?)
- Documentation has been refreshed and expanded to keep pace with the introduction of new features.
- Sub-array indexing bugs and inconsistent behavior across functions have been resolved.
- Several CMake build issues were fixed, including compatibility with Windows, vcpkg, and CUDNN.
For more information on these and other changes, you may visit this version’s patch notes.
🐍 New in v3.10: Python Bindings
Python users can now leverage ArrayFire for fast, GPU-accelerated computing, utilizing a user-friendly API that seamlessly integrates into existing Python workflows.
Here’s a quick example:
import arrayfire as af
# Set backend and device (optional: 'cuda', 'opencl', 'oneapi', 'cpu')
af.setBackend(af.BackendType.cuda)
af.setDevice(0)
# Create two 5x5 arrays on the GPU
a = af.randu((5, 5))
b = af.randu((5, 5))
# Perform element-wise addition and matrix multiplication
c = a + b
d = af.matmul(a, b)
# Print the result
print(c, "Element-wise Sum")
print(d, "Matrix Product")
ArrayFire’s Python bindings deliver the same performance and flexibility you’re accustomed to from C++ to your preferred scripting environment.
This is still a work in progress, and we would appreciate any feedback you may have. For more information, visit the arrayfire-py GitHub page.
📈 Performance
One of ArrayFire’s core strengths is performance, so for those interested in the numbers, here are some graphs comparing ArrayFire Python against other packages for some common operations:
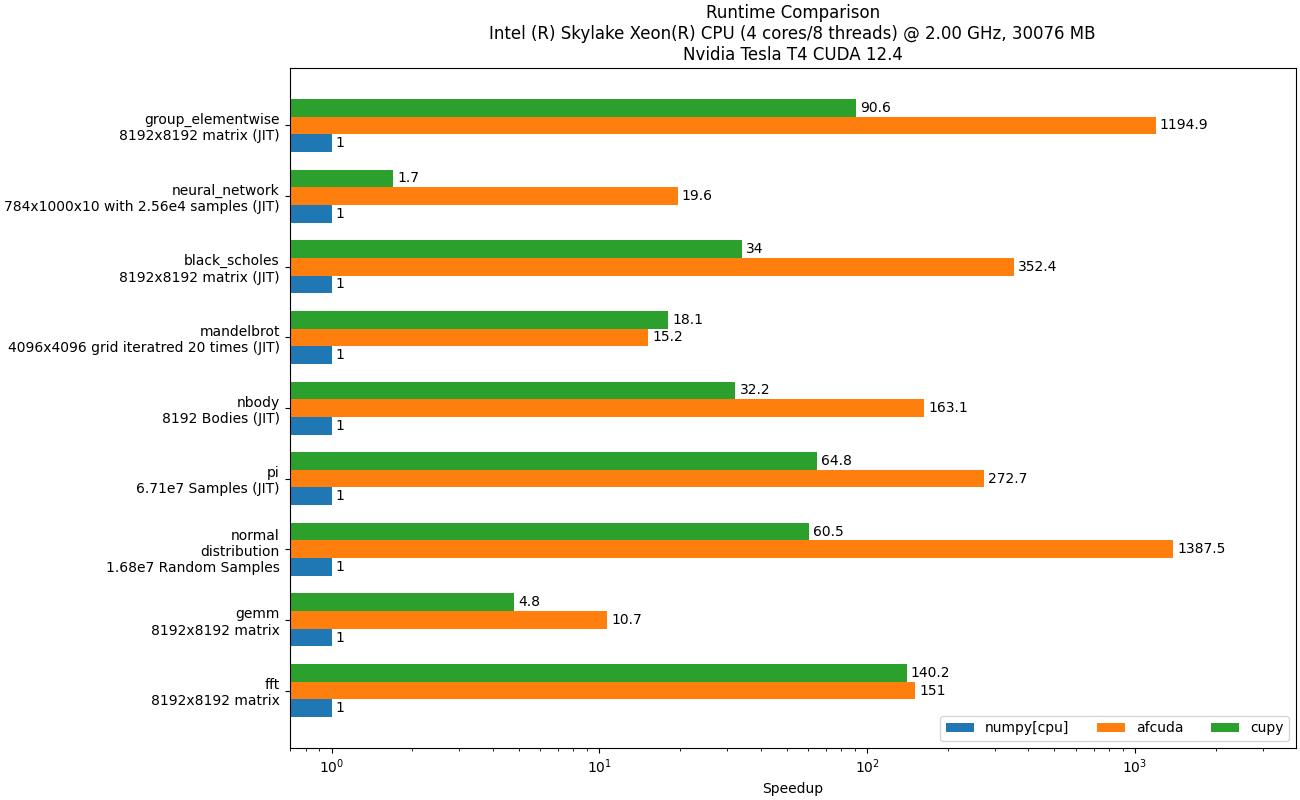

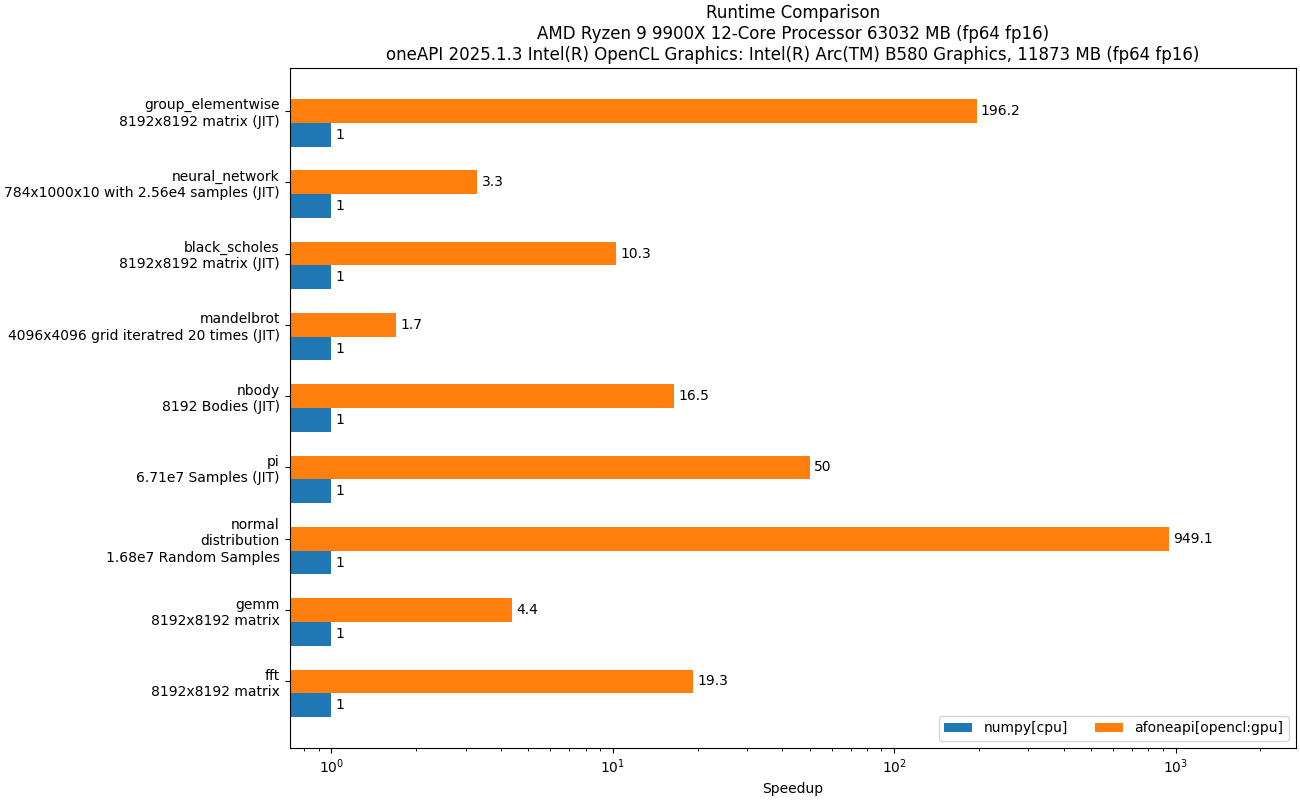
These graphs were generated with this benchmark code using the ArrayFire C Libraries v.3.10
📦 Get It Now
You can get the latest version of ArrayFire v3.10 from the releases page on GitHub, use our official installers, or install it via your preferred package manager.
We encourage you to open issues or contribute PRs if you’d like to help push the project forward. This release includes contributions from long-time maintainers and first-time collaborators—thank you all!
❤️ Thank You!
A huge thanks to everyone in the ArrayFire community for your feedback, code contributions, and continued support. With your help, we’re building a high-performance computing library that makes scientific computing faster, simpler, and more enjoyable.
Stay tuned for more updates!